Классификация целей при работе гидроакустических станций с задействованием автоматического распознавателя речи (2018)
В. Спиридонов,
кандидат технических наук
Классификация целей - важнейшая задача корабельных гидроакустических станций (ГАС) при освещении подводной обстановки. В настоящее время оператор ГАС является наиболее подготовленным специалистом в этой области, но и для него достаточно сложно одновременно классифицировать большое количество регистрируемых звуков природного и техногенного происхождения, а также излучаемых целью (подводная лодка (ПЛ), торпеда или судно). В связи с этим специалисты германской кампании "Атлас электроник" в помощь оператору станции разрабатывают программный продукт, который автоматизирует процесс классификации.
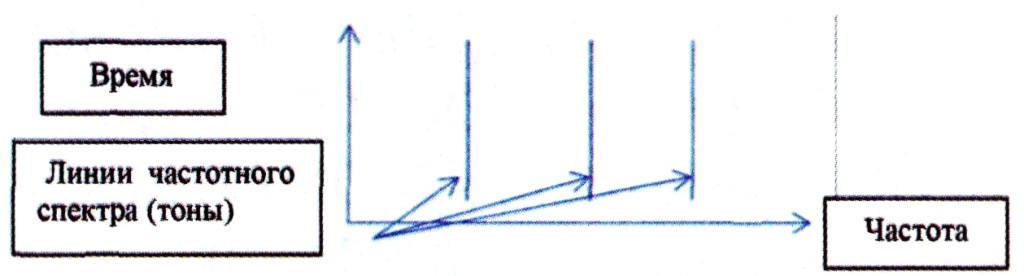 |
| Рис. 1. Упрощенный фрагмент LOFAR-анализа, отражающего взаимосвязь межу частотой и временем |
 |
| Рис. 2. Трехмерная спектрограмма, полученная при проведении LOFAR-анализа |
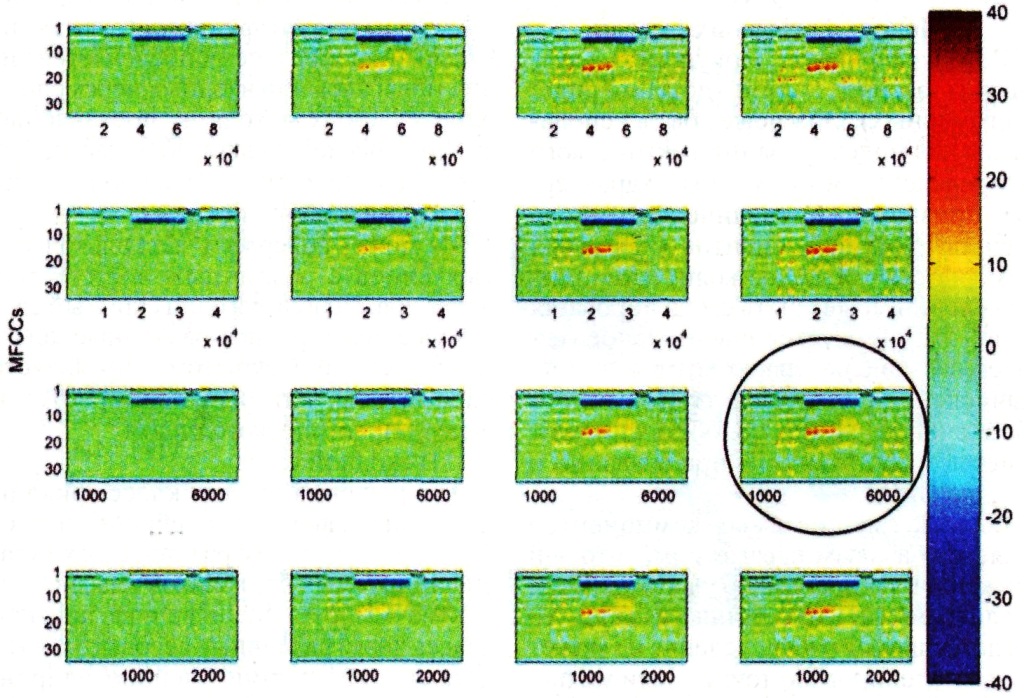 |
| Рис. 3. Визуализация комбинации разных параметров (слева направо -увеличение параметра лифтрации; сверху вниз -увеличение длины временных окон) |
 |
| Рис. 4. Матрица, отражающая уровень классификационных возможностей при использовании GMM и MFCC обучающей базы данных |
 |
| Рис. 5. Матрица, отражающая уровень классификационных возможностей при использовании GMM и MFCC в тестирующей системе |
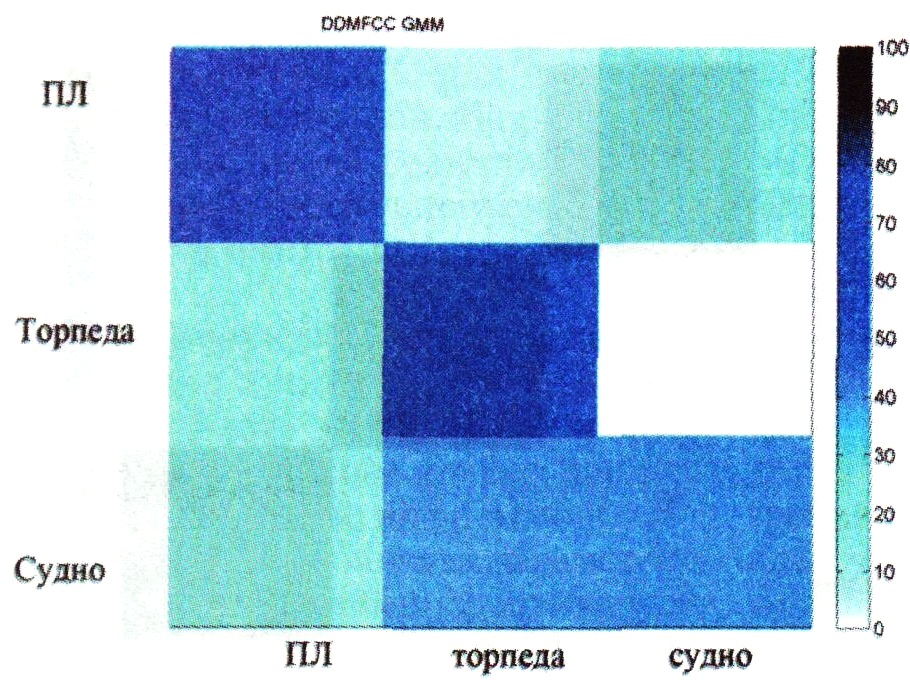 |
| Рис. 6. Матрица, отражающая уровень классификационных возможностей при использовании GMM и DDMFCC в тестирующей системе |
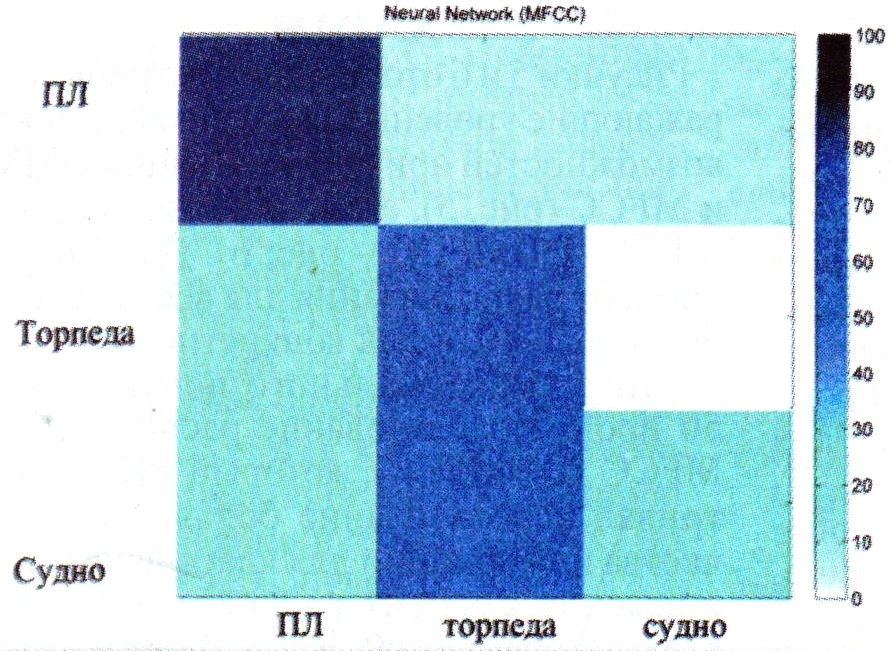 |
| Рис. 7, Матрица, отражающая уровень классификационных возможностей при использовании NN и MFCC в тестирующей системе |
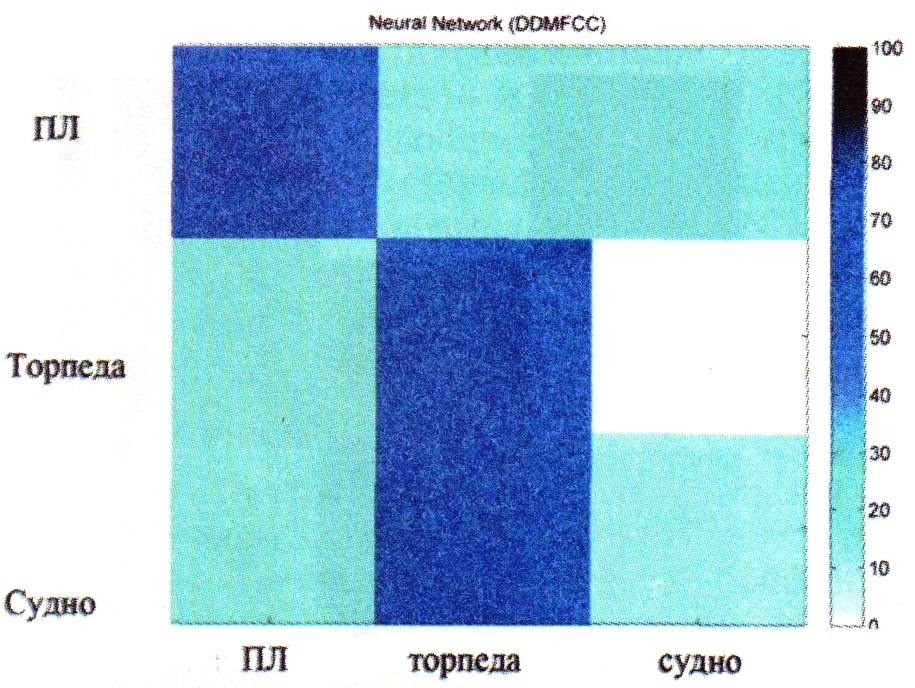 |
| Рис. 8 Матрица, отражающая уровень классификационных возможностей при использовании NN и DDMFCC в тестирующей системе |
Используемый в настоящее время программный продукт предназначен прежде всего для выявления линейно расположенного набора спектральных линий, например, с помощью DEMON-анализа (Detection of Envelope Modulation on Noise - анализ амплитудной модуляции шума) и LOFAR-анализа (Low Frequency Analysis and Recording - низкочастотный анализ, см. рис. 1 и 2). Исходя из линейной расстановки отличительных признаков (тонов), обнаруженный объект и классифицируется.
Например, DEMON-анализ позволяет определить скорость вращения вала и число лопастей, а LOFAR-анализ - выявить основные частоты, характеризующие работу двигателя внутреннего сгорания. Но этих отличительных признаков может быть недостаточно для надежной классификации цели. Они основываются только на характерных для цели спектральных линиях.
Для того чтобы использовать в полном объеме звуковую информацию о цели, важны также и другие ее признаки. Выявление новых признаков основывается на изучении принятых звуковых сигналов от различных антенн.
Для разработки эффективного автоматического классификатора германские
специалисты использовали подход, базирующийся на моделях слуховой системы человека. Автоматическое распознавание речи (ASR - Automatic Speech Recognition) предполагает применение нескольких программных средств, обеспечивающих решение задачи классификации целей.
Селекция новых признаков основывается на изучении и нормировании процесса распознавании речи и классификации звука. Алгоритмы и признаки, используемые для распознавания речи, демонстрируют высокий процент распознавания слов.
Для максимального использования акустической информации были применены мел-частотные кепстральные коэффициенты (MFCC - Mel Frequency Cepstral Coefficients), четко характеризующие признаки (свойства) объектов. MFCC могут быть представлены как параметризация спектра, позволяющая безошибочно описать его с помощью небольшого числа параметров. Параметризация оптимизирована для частотного восприятия человеком.
MFCC используются в сочетании с другими классификаторами: моделью Гауссовых смесей (GMM - Gaussian Mixture Model), которая представляет собой взвешенную Гауссианскую сумму, широко используемую в распознавании речи дикторов, а также с нейронными сетями (NN - Neural Networks). Оба классификатора широко применяются при автоматическом распознавании речи.
Данный инструментарий и признаки также были использованы в гидроакустических станциях, что потребовало проведения дополнительных исследований, которыми занимались специалисты компании "Атлас электроник". Ими была создана и протестирована структурная основа (база данных, набор отличительных признаков и классификаторы) для классификации звуковых данных, получаемых от ГАС.
База данных, используемая в исследованиях, включала различные звуковые файлы, сгенерированные различными судами, объектами и средой (например, пуск торпед, звуки, издаваемые китами). Для проведения исследования все эти данные были структурированы и систематизированы. Звуковые файлы были урезаны и нормированы для получения звуковых данных, характеризующих конкретный класс целей. В итоге удалось сформировать три класса целей: ПЛ, торпеды и суда.
Отличительные признаки. Мел-частотные кепстральные коэффициенты широко используются при автоматическом распознавании речи. MFCC - это своеобразное представление энергии спектра сигнала. Преимущество его применения заключается в том, что задействуется весь спектр сигнала.
Этот спектр исходного сигнала образуется с помощью преобразования Фурье, что позволяет учитывать его волновую природу при дальнейшем анализе. Затем спектр проецируется на специальную мел-шкалу, благодаря которой удается выделить наиболее значимые для восприятия человеком частоты.
После этого рассчитывается логарифм абсолютного значения каждого спектра и осуществляется обратное преобразование Фурье-логарифма частотного спектра, которое называется кепстр, и затем он визуализируется как спектр спектра. При этом описывается весь спектр целиком.
Фильтрование в кепстральной области называется лифтрация (littering: аналог спектр <-> кепстр). Мел-частотные кепстральные коэффициенты отличаются от кепстра единицами частотного масштаба. Мел-частотный масштаб является логарифмической частотной шкалой. Он опирается на основной тон речевого сигнала, оцененного измерениями. Выше 500 Гц слушающие производят выборку во все большем и большем интервале для того, чтобы произвести одинаковые приращения основного тона. Мел-частотный масштаб отражает эти результаты.
Опорной точкой является частота 1000 Гц, которая приравнивается к 1000 мел. По этой причине в распознавании речи мел-частотный масштаб используется для того, чтобы получить частотное масштабирование, эквивалентное частотному восприятию человека. MFCC рассчитываются исходя из входного сигнала si, длиной N (si; i = 1, ..., N), в ходе осуществления семи шагов:
1. Предварительное выделение входного сигнала: ,
sn = si - а • si-1 (1), где sn - выделенный сигнал; si - сигнал на временном шаге i; а - выделенный параметр; si-1 сигнал на временном шаге i - 1.
2. Предварительно выделенный входной сигнал sn подвергается разложению на совмещаемые сегменты (фреймы) с использованием соответствующей оконной функции (например, взвешивающей функцией Хемминга). Таким образом, для MFCC достигается необходимый период времени разрешения.
3. Для каждого сегмента (фрейма) спектр рассчитывается с использованием быстрого преобразования Фурье (FFT). Полученный спектр нужно расположить на мел-шкале. Для этого используются окна, равномерно расположенные на мел-оси. Простым перемножением векторов спектра сигнала и оконной функции вычисляется энергия сигнала, которая попадает в каждое из окон анализа. Получается некоторый набор коэффициентов, но это еще не те MFCC, которые требуются. Пока их называют мел-частотными спектральными коэффициентами.
4. На следующем этапе мел-частотные спектральные коэффициенты возводят в квадрат и рассчитывают логарифм абсолютного значения каждого спектра.
5. Логарифмический спектр преобразуется в мел-частотные линии с использованием мел-треугольных полосовых фильтров (мел-фильтр). Далее остается только получить из них мел-частотные кепстральные коэффициенты, или "спектр спектра". Для этого применяют дискретное косинусное преобразование Фурье.
6. Отфильтрованный через мел-фильтры спектр затем декоррелируется с использованием дискретного косинусного преобразования (Discrete Cosine Transformation - DCT). Полученные коэффициенты и есть MFCC.
7. На конечном этапе MFCC подвергаются лифтрации для выделения коэффициентов высокого порядка.
Как правило, после лифтрации первые 13 коэффициентов используются в качестве вектора, характеризующего признаки при автоматическом распознавании речи. Дополнительно к этим 13 MFCC большее количество характеризующих признаков может быть рассчитано для того, чтобы использовать временную информацию об изменении MFCC. Во-первых, Delta-MFCC (DMFCC, то есть небольшие изменения) могут быть рассчитаны сверх временного окна. Они отображают изменения в каждом коэффициенте аналогично скорости. Изменение этой скорости может быть рассчитано, ведя к Delta-Delta-MFCC (DDMFCC), которые могут быть интерпретироваться как ускорения MFCC.
При осуществлении расчета MFCC имеется набор различных параметров для выбора, например длина временного окна, или число MFCC для применения, или сила лифтрации. На рисунке 3 показано влияние на величину MFCC изменения длины временного окна (сверху вниз) и параметра лифтрации (слева направо).
Сравнивая два изображения (фрейма) - верхнее левое и нижнее правое, видно, что по контрасту для классификации более подходит нижнее правое, так как оно содержит больше информации. Обведенная кругом комбинация параметров была выбрана как компромисс между контрастом и разрешающей способностью по времени.
Классификаторы. Таковых имеется и используется множество. В данном исследовании были выбраны: модель Гауссовых смесей и нейронные сети. GMM широко применяется при распознавании речи совместно с MFCC. Нейронные сети также представляют интерес из-за их математической простоты и возможности использования при решении широкого спектра задач.
Обоим классификаторам требуется обучение. Поэтому подбор базы данных был разделен на два комплекта: для обучения и проведения тестирования. Второй используется как инструментарий, обеспечивающий количественную оценку классифицируемых данных, но он не годится для обучения.
А. Модель Гауссовых смесей
GMM взвешивает совокупность Гауссовских распределений (потенциально многомерных). Она может быть использована для моделирования фактического распределения многомерных характерных признаков. С увеличением числа смешиваемых компонентов и входных размерностей большее количество распределений может быть смоделировано, но при этом требуется значительное увеличение вычислительных возможностей. Вычисления с помощью программного обеспечения MATLAB обеспечивают приемлемый интерфейс при создании и отладке GMM.
Число к смешиваемых компонентов является базовым параметром, который должен быть правильно выбран. Если число компонентов слишком мало, то представляемое распределение не может быть смоделировано точно. Если же оно слишком велико, то итоговая модель является просто правильной для заданных признаков.
Для обучения используются данные из обучающего набора базы данных. Для каждого класса рассчитываются MFCC-вектора, характеризующие признаки, которые затем используются при обучении GMM для каждого класса. Для файла, предназначенного для те--стирования, рассчитываются вектора, характеризующие признаки, и рассчитывается вероятность каждого вектора, характеризующего признак с точки зрения принадлежности его к каждому классу - GMM. Затем отбирается класс с наивысшей вероятностью.
Б. Нейронные сети
Они представляют собой другой инструментарий, используемый для решения задач обнаружения и классификации. Нейронная сеть состоит из простых элементов, которые объединены для решения специфичных задач. Нейрон имеет вход и выход, а также функцию активации (например, функцию гиперболического тангенса). В соответствии со входом отрегулирован выход. Вторым базовым элементом NN является связь между нейронами. Она имеет весовые коэффициенты, которые определяют воздействие нейрона на следующий нейрон. NN по существу разделена на три слоя нейронов:
1. Входной слой.
Этот специализированный слой является входом NN и в типовом варианте имеет линейную функцию активации. Число нейронов в нем определяется числом признаков или входных переменных, определяемых исходя из поставленной специфической задачи. Каждый нейрон соединен с нейроном в следующем слое.
2. Промежуточный слой.
NN может содержать несколько скрытых слоев с различным количеством нейронов. Используя один скрытый слой, NN уже может решать различные задачи. Число нейронов скрытого слоя является параметром, который подбирается на основе практического опыта.
3. Выходной слой.
Для решения задачи классификации целей число выходных нейронов должно быть равным числу различаемых (классифицируемых) признаков класса.
NN суммирует специфичные признаки класса через различные весовые коэффициенты соединений "нейрон-нейрон". Одним из преимуществ перед GMM является то, что для классификации требуется только одна NN, тогда как при использовании GMM их нужно три.
Обучающая база данных должна быть гармонизирована, то есть иметь одинаковое количество обучающих данных и рассчитанных характеризующих признаков для каждого класса. Для каждого вектора, характеризующего признак, выход сети должен быть определен.
Обучающий алгоритм затем корректируется весовыми коэффициентами между разными нейронами для того, чтобы получить желаемый выход. Для тестирующего файла вектора характеризующие признаки просчитываются и подаются в сеть. Выходом сети являются классификационные результаты.
Результаты исследований. Рисунки с 4 по 6 отражают результаты по классификации в виде матриц, иллюстрирующих уровень классификационных возможностей. Каждый ряд матричных неопределенностей представляет собой классификационные результаты для одного класса. Цвет каждой ячейки определяет процент (черный -100 %, белый - 0 %) классификации для данной комбинации классов.
На рисунке 4 черная диагональ обозначает идеальную классификацию. Этот рисунок представляет результаты обучающей базы данных, использующей MFCC для определения характерных признаков и GMM-классификатор. Он показывает идеальную классификацию, где каждый характеризующий признаки вектор промаркирован в соответствии с надлежащим классом.
Такой результат для обучающей базы данных был ожидаем, так как показатели использовались для построения эталонов. Результаты, полученные для NN, MFCC, DMFCC и DDMFCC, здесь не приводятся, но и они продемонстрировали идеальную классификацию. На рисунках с 5 по 8 показаны диаграммы классификационных результатов для тестирующей системы (тестирующей базы данных), использующей два разных классификатора и два разных типа характеризующих признаков.
A. GMM
Рисунки 5 и 6 отображают матрицы, отражающие уровень классификационных возможностей при использовании GMM и MFCC (рис. 5), а также расширенного MFCC (DDMFCC - рис. 6). Для MFCC процент распознавания для всех классов был около 40, а для конкретного класса достигал максимального показателя 50 % Использование расширенных MFCC (DDMFCC), который предусматривал использование большего количества информации для классификации, повысило процент распознавания для всех классов до 60, а для одного класса распознавание достигло максимум 75 % Для обоих классификационных признаков матрицы классификационных возможностей демонстрируют отсутствие заметной путаницы между классами. Но сама диаграмма меняется между двумя типами характеризующих признаков.
Б. Нейронная сеть
Рисунки 7 и 8 отображают матрицы, показывающие уровень классификационных возможностей при использовании NN и MFCC (рис. 7) и расширенных MFCC (DDMFCC - рис. 8). Применение характеризующих признаков MFCC обеспечило процент распознавания для NN, равный 60, а для конкретного класса распознавание достигло 80 % Использование DDMFCC привело к небольшому снижению процента распознавания до 50 с максимальным показателем 75 %
Очевидно, что параметры для NN могут быть адаптированы в обеспечение увеличения размерности вектора, характеризующего признаки.
Результаты исследований, проведенных специалистами компании "Атлас электроник", показывают возможность применения инструментария на основе автоматического распознавания речи для классификации целей, обнаруженных гидроакустической станцией. Требуемые параметры характеризующих признаков MFCC и классификаторы могут быть отрегулированы. Также имеется возможность расширения и усовершенствования обучающей базы данных (программы).
За счет использования этих возможностей может быть создана система с большим процентом распознавания шумов, регистрируемых ГАС, а также их классификации. Ее можно будет использовать в качестве помощника оператора станции. Например, она обеспечит определение приоритетов всем объектам в ситуации, когда обнаружено множество неизвестных целей.